

✨ 시작 질문: 약을 오래 복용할수록 건강해진다?
한 예를 보자.
“당뇨병 환자가 3년간 메트포르민을 복용했더니 합병증 발생률이 낮아졌다.”
이때 우리는 이런 질문을 던질 수 있다.
📌 “그 환자가 메트포르민을 안 먹었더라면 어땠을까?”
📌 “혹시 건강해서 계속 약을 복용한 것 아닐까?”
📌 “약을 더 오래 먹는 사람은 원래부터 상태가 좋은 건 아닐까?”
👉 이런 질문은 단순한 PSM이나 IV 분석으로는 해결이 어렵다.
시간에 따라 처치가 바뀌고, 그 처치에 영향을 주는 변수(예: 건강 상태)도 같이 변하기 때문이다.
이때 사용하는 것이 바로 Marginal Structural Models(MSM)이다.
🔍 MSM이 필요한 이유: Time-varying Confounding
✅ 개념 설명
시간에 따라 변하는 confounder는 MSM이 등장한 가장 큰 이유다.
예를 들어, 당뇨병 환자의 혈당 수치는 시간에 따라 바뀌고,
혈당 수치는 약 복용 여부에 영향을 미치며,
동시에 향후 합병증 발생에도 영향을 준다.
이렇게 처치에 영향을 주면서, 결과에도 영향을 주는 시간변화 변수를 time-varying confounder라고 한다.
🔄 일반 모델의 한계
일반적인 회귀모형에서 혈당 수치를 공변량으로 통제하려 하면 문제가 생긴다.
왜냐하면 혈당 수치는 과거 약 복용의 결과이기도 하기 때문이다.
즉, 이 변수는:
- Confounder이자
- Mediator(중재변수)인 것.
이런 상황에서는 전통적인 회귀모델이나 PSM은 편향된 결과를 낸다.
💡 여기서 등장하는 방법이 MSM (Marginal Structural Model)
MSM은 시간가변 치료와 시간가변 confounder가 존재할 때,
인과효과를 정확히 추정할 수 있는 방법이다.
📌 핵심은 다음 두 가지:
- Inverse Probability Weighting(IPW)
→ 시점별 처치를 받았을 ‘확률’의 역수를 가중치로 부여
→ 치료 여부가 무작위였던 것처럼 만든다 (pseudo-population) - Marginal Structural Model (MSM)
→ 이 가중치를 사용해서 구조모델(structural model)을 적합
→ 시간의 흐름을 반영한 인과추정 가능
💡 MSM의 기본 아이디어
“모든 사람이 특정 시간대에 어떤 처치를 받았다고 가정했을 때의 평균 결과는?”
📌 Marginal (주효과): Confounder로부터 자유로운 전체적인 평균 효과
📌 Structural Model: 인과관계 구조에 기반한 모델
📌 Weighting: 가중치를 부여해 confounder가 통제된 가상의 모집단을 만드는 접근
✍ MSM 구성 단계 요약
1. 모든 시점별 처치 확률 추정 (Propensity Score for each time)
2. Inverse Probability Weight (IPW) 계산
누적 처치 확률을 곱하여 역수로 변환

3. 가중치를 적용한 가상의 ‘균형 잡힌 집단’ 생성
4. 그 집단에 대해 결과(Y)를 모델링 → MSM으로 ATE 추정
🔁 Inverse Probability Weighting (IPW)이란?
MSM이 돌아가려면, 우선 가중치(weight)를 만들어야 한다.
📌 핵심 개념
- 과거 정보를 기준으로,
실제로 받은 처치의 확률을 예측한다. - 그 확률의 역수를 가중치로 사용한다.
📌 이게 왜 필요한가?
확률이 낮은 처치를 받은 사람은 ‘운이 좋게 받은 것’처럼 간주
→ 그래서 그 사람에게 더 많은 가중치를 줘야 한다.
📌 예:
처치 확률이 0.2 → 가중치 1/0.2 = 5
처치 확률이 0.8 → 가중치 1/0.8 = 1.25
→ 데이터 내의 처치 할당 불균형을 교정함.
📈 가중 vs 비가중 추세 비교: MSM의 효과 시각화 예시
아래 그래프는 IPTW 적용 전후의 심혈관 사건률 추세를 보여준다.

가중치 없이 보면 시간이 지날수록 사건률이 꾸준히 증가하는 것으로 보이지만,
IPTW를 적용한 추세에서는 그 증가폭이 훨씬 완만해진다.
이는 초기에 건강했던 환자일수록 약을 계속 복용한 경향이 있고,
건강이 악화된 환자는 중간에 치료를 중단했을 가능성이 있다는 점에서 confounding이 존재했음을 시사한다.
📌 다시 말해, IPTW 없이 단순히 ‘약을 오래 먹은 사람’만 분석하면,
‘원래 건강했던 사람’의 효과를 착각하게 되는 것이다.
→ MSM은 이런 왜곡을 교정해주는 역할을 한다.
📐 MSM 수식 구조

- A는 시간에 따라 달라지는 처치
- W는 시간별 confounder
- Y는 최종 결과
🏥 임상 예시: 당뇨병 환자의 치료 이력과 심혈관 질환 위험
“환자들이 매년 혈압약 복용 여부를 기록했고,
5년 뒤 심혈관 질환 발생 여부(Y)를 관찰했다고 하자.”
📐 이때 변수 구조
| 시점 | 변수 종류 | 예시 |
| t=0 | Confounder | 나이, 성별, 기저 혈압 |
| t=1 | Treatment | 1년 차 혈압약 복용 여부 |
| t=1 | Confounder | 1년 차 혈압 수치 |
| t=2 | Treatment | 2년 차 혈압약 복용 여부 |
| t=2 | Confounder | 2년 차 혈압 수치 |
| ... | ... | ... |
| t=5 | Outcome (Y) | 심혈관질환 발생 여부 (0/1) |
t 시점의 혈압 수치는 t+1 시점의 혈압약 복용 여부에 영향을 주며,
동시에 t=5 시점의 심혈관 질환 발생(Outcome)에도 영향을 미친다.
→ Time-varying Confounder

✅ 데이터 구성 예
- Aₜ: 시점별 약물 복용 여부 (예: 인슐린 처방)
- Lₜ: 시점별 혈당, 체중, 혈압 등 생체지표
- Y: 3년 내 심근경색 발생 여부
📌 문제 상황
- 혈당이 높을수록 인슐린 처방될 확률↑
- 하지만 혈당은 동시에 심혈관질환 발생률에도 영향
👉 혈당을 단순히 모델에 넣으면
confounder로 조정하면서 동시에 mediator로 차단하는 오류 발생
💡 해결 전략: MSM 적용
- 각 시점에서 인슐린 처방을 예측하는 로지스틱 모델로 SW 계산
- 이 SW를 이용해 Y ~ A₁ + A₂ + A₃ 모델을 가중치 회귀로 적합
- 각 시점의 처치가 결과에 미친 효과 β₁, β₂, β₃를 추정
🧪 Python 코드 예시 (간단 구현)
import pandas as pd
import numpy as np
from sklearn.linear_model import LogisticRegression
import statsmodels.api as sm
import matplotlib.pyplot as plt
# 샘플 데이터 생성 (예시)
# A1, A2, A3: 각 시점의 처치 / L1, L2, L3: 시점별 confounder / Y: 결과
np.random.seed(0)
n = 200
df = pd.DataFrame({
'A1': np.random.binomial(1, 0.5, n),
'A2': np.random.binomial(1, 0.5, n),
'A3': np.random.binomial(1, 0.5, n),
'L1': np.random.normal(0, 1, n),
'L2': np.random.normal(0, 1, n),
'L3': np.random.normal(0, 1, n),
'Y': np.random.binomial(1, 0.3, n)
})
# 1. Stabilized Weight 계산
def calc_sw(data, treatment_cols, confounder_sets):
sw = np.ones(len(data))
for i, t in enumerate(treatment_cols):
L = confounder_sets[i]
# Numerator: 조건 없이 처치 확률 예측
model_n = LogisticRegression().fit(data[[t]], data[t])
p_n = model_n.predict_proba(data[[t]])[:, 1]
# Denominator: 해당 시점 confounder 포함
model_d = LogisticRegression().fit(data[L], data[t])
p_d = model_d.predict_proba(data[L])[:, 1]
sw *= (p_n / p_d)
return sw
# 2. MSM 적합
def msm_model(data, treatment_cols, outcome_col, weight):
X = sm.add_constant(data[treatment_cols])
y = data[outcome_col]
model = sm.WLS(y, X, weights=weight).fit()
return model.summary()
# 적용
treatment_cols = ['A1', 'A2', 'A3']
confounder_sets = [['L1'], ['L2'], ['L3']]
weights = calc_sw(df, treatment_cols, confounder_sets)
# MSM 적합
print(msm_model(df, treatment_cols, 'Y', weights))
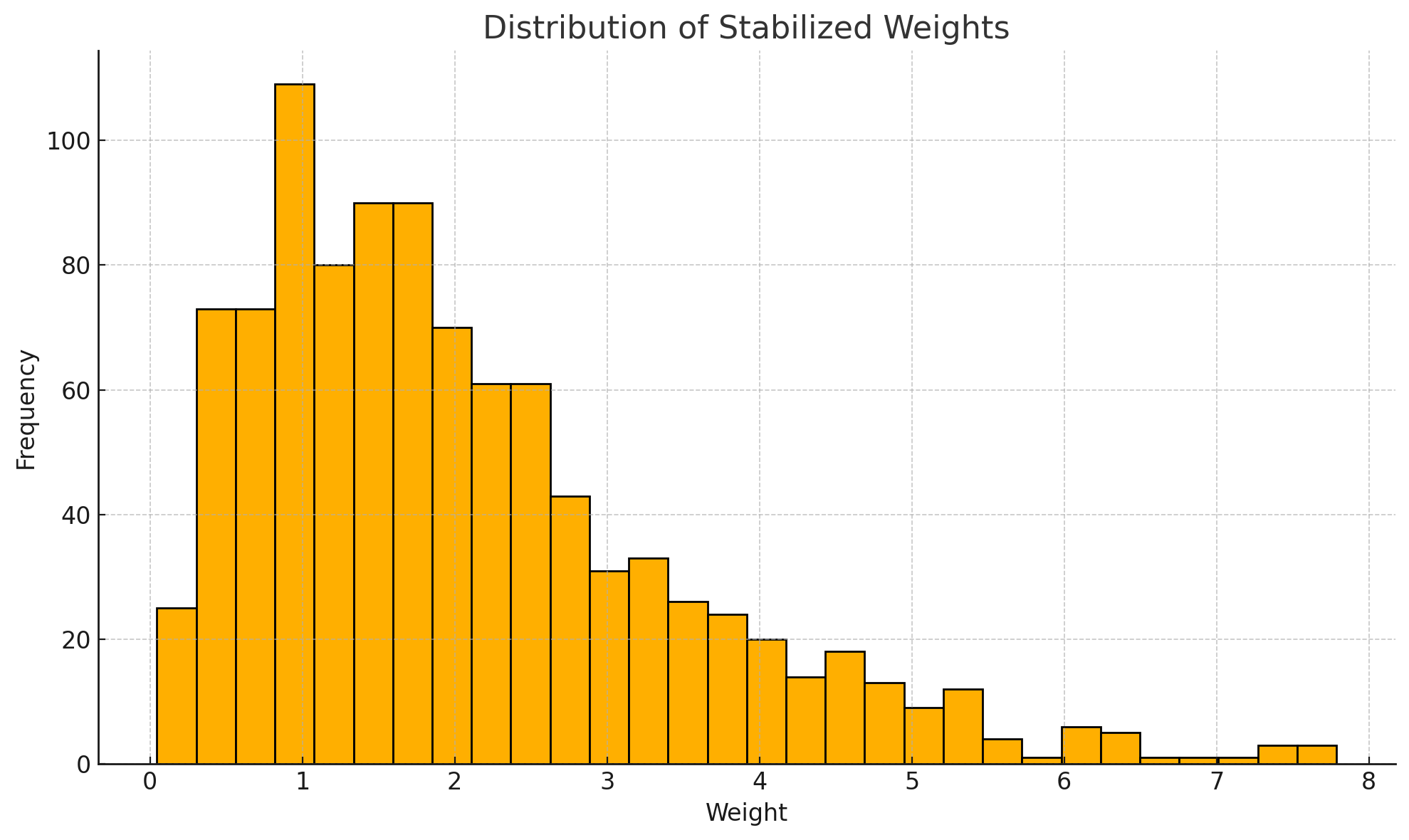
# 3. Stabilized Weights 분포 시각화
plt.hist(weights, bins=30, edgecolor='black')
plt.title("Distribution of Stabilized Weights")
plt.xlabel("Weight")
plt.ylabel("Frequency")
plt.grid(True)
plt.show()
✅ MSM 사용 전 체크리스트
| 항목 | 질문 |
| 시간가변 Confounder | 치료와 결과 모두에 영향을 주는 시점별 변수 있는가? |
| Confounder 조작 | 시간 흐름에 따라 confounder가 치료에 영향 주는 구조인가? |
| 처치 변화 | 시간이 지남에 따라 치료 여부가 바뀌는가? |
| 관측 데이터 | 반복 측정이 가능한 longitudinal data인가? |
📉 시각화 제안
- IPTW의 분포 히스토그램: extreme weight 존재 여부 확인
- MSM 적합 전후의 위험률 차이 plot
- 시간별 치료 효과 βₜ line plot
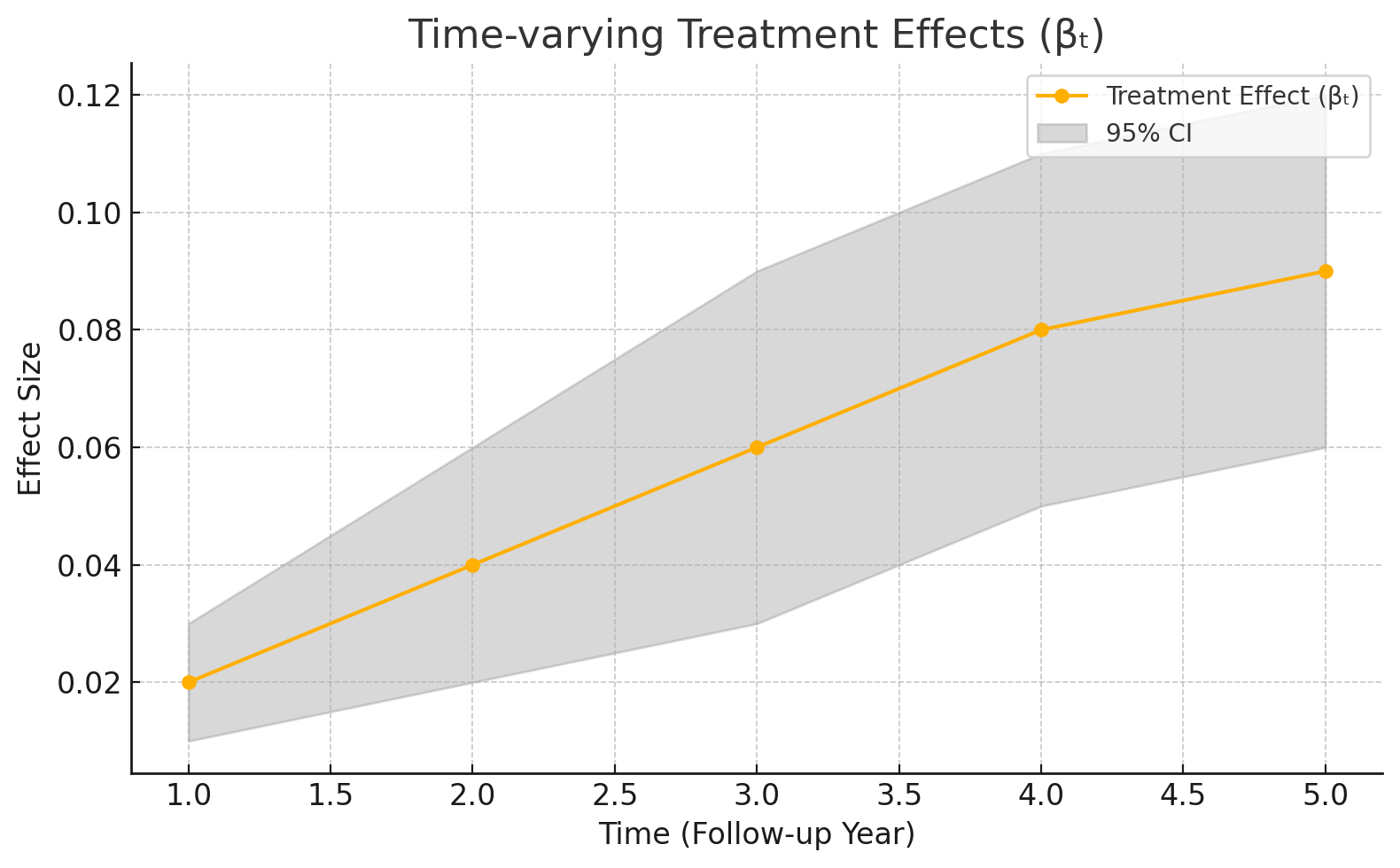
👉 시간에 따라 달라지는 치료 효과(βₜ) 그래프
시간이 지남에 따라 효과가 점진적으로 증가하는 추세가 보이며, 이는 누적 복용이나 시간효과의 존재를 시사할 수 있다.
또한 각 시점별 신뢰구간을 함께 확인함으로써 통계적 유의성과 효과의 일관성을 평가할 수 있다.
📌 MSM과 다른 기법 비교
| 기법 | 시간가변 Confounder | 시간반영 인과추정 | 강도 | 비고 |
| PSM | X | X | 중간 | baseline만 사용 |
| IPTW | △ | △ | 보통 | 시간가변 처리 어려움 |
| MSM | ✅ | ✅ | 강함 | 설계 복잡하지만 유연성 높음 |
| TMLE | ✅ | ✅ | 매우 강함 | 이론은 복잡, 구현은 econml로 가능 |
💬 요약: MSM은 언제 쓰는가?
- 치료가 반복되고, 시간이 지나며 치료 여부가 바뀌며,
- 그 치료를 결정짓는 건강 상태(혼란변수)가 결과에도 영향을 주는 경우
📌 가장 대표적인 예시:
만성질환 환자의 치료 이력 추적
(당뇨병, 고혈압, HIV 치료 등)
🧠 실무 팁 요약
| 팁 | 내용 |
| confounder 정의 | 시간가변 변수들을 포함해야 함 |
| extreme weight | 0.1 < IPTW < 10 사이로 유지, trimming 필요 |
| 모델 적합 | stabilized weight + robust SE 사용 |
| sensitivity 분석 | 다른 bandwidth, 변수 구성으로 반복 테스트 |
'실전 인과추론' 카테고리의 다른 글
| 《실전 인과추론 시리즈 ⑦ – TMLE 해부하기》 (2) | 2025.05.19 |
|---|---|
| 《실전 인과추론 시리즈 ⑤ - G-Computation 해부하기》 (1) | 2025.05.13 |
| 《실전 인과추론 시리즈 ④ - RDD(단절설계) 해부하기》 (2) | 2025.05.12 |
| 《실전 인과추론 시리즈 ③ - Difference-in-Differences, DiD 해부하기》 (1) | 2025.05.11 |
| 《실전 인과추론 시리즈 ② - Instrumental Variable(도구변수) 해부하기》 (0) | 2025.05.08 |