
✨ 시작 질문
“한 환자가 혈압약을 먹고 나서 혈압이 내려갔다면,
그 환자가 약을 먹지 않았다면 어땠을까?”
이 질문은 단순해 보이지만, 인과추론에서는 가장 본질적인 의문이다.
그런데 여기엔 현실적인 제약이 있다.
우리는 한 환자에 대해 오직 하나의 결과만 관찰할 수 있기 때문이다.
- 약을 먹은 환자 → 결과: 혈압이 낮아졌다 ✅
- 그런데 약을 먹지 않았을 때의 그 환자 결과는 관찰 불가능하다 ❌
이처럼 동일한 개인의 두 개의 결과를 동시에 알 수 없는 상황을
반사실적(counterfactual) 문제라고 한다.
🔍 왜 어렵나?
다음 중 어떤 설명이 진짜일까?
- ✅ 약을 먹었기 때문에 혈압이 낮아졌다
- ❌ 원래 혈압이 내려가던 사람이 약도 챙겨먹은 것뿐이다
우리가 약의 ‘효과(effect)’를 알고 싶다면,
진짜로 약이 없었더라면 결과가 어땠는지를 추정해야 한다.
하지만 현실에선 그 장면을 절대 볼 수 없다.
👉 그래서 필요한 게 G-Computation이다
G-Computation은 관측 가능한 데이터에서
‘약을 먹지 않았더라면 어땠을까?’를 시뮬레이션하는 도구다.
예를 들어 이렇게 해석할 수 있다:
- 실제로 약을 먹은 환자에게
→ “약을 안 먹었더라면”을 가정하고 결과를 예측 - 실제로 약을 안 먹은 환자에게
→ “약을 먹었더라면”을 가정하고 결과를 예측 - 그 둘의 평균 차이를 구하면
→ 모든 환자에게 약이 미친 인과효과(ATE)가 된다
📌 핵심은 결과(Y)를 잘 예측할 수 있는 모델이 있다면,
실제로 관찰되지 않은 결과(counterfactual)도 예측할 수 있다는 아이디어다.
💬 한 줄 요약
G-Computation은 관측된 결과만으로는 알 수 없는 ‘다른 세계의 나’를 상상해서 인과효과를 계산하는 방법이다.
✅ G-Computation이 적합한 상황
| 상황 | 이유 |
| 🔢 Outcome이 연속형 변수일 때 | 예측 모형이 정밀하게 결과값을 추정할 수 있음 (예: 혈압, 체중, 혈당 수치 등) |
| 🎯 Confounder가 대부분 관측 가능할 때 | 인과추론의 전제 조건 중 하나인 “No unmeasured confounding”을 만족시킬 수 있음 |
| 🧠 모델을 통해 해석력을 확보하고 싶을 때 | 선형회귀, RandomForest 등으로 구조적으로 결과에 영향을 미치는 요인을 파악 가능 |
| 🔄 다양한 시나리오에서 counterfactual을 시뮬레이션하고 싶을 때 |
특정 환자가 치료를 받았을 때/받지 않았을 때 결과를 모두 가정할 수 있음 |
| 💡 모델링 자유도가 중요한 연구 설계일 때 | 머신러닝 적용이나 비선형 예측이 쉬운 접근 방식임 |
⛔ G-Computation이 어려운 상황
| 상황 | 이유 |
| ⚠️ 중요한 confounder가 누락된 경우 | 모델이 아무리 좋아도 인과효과 추정은 왜곡됨 |
| 🧩 Outcome이 이분형인데 클래스 불균형이 심할 때 |
예측 모델이 제대로 학습되지 않아 ATE 추정도 왜곡 가능 |
| 📉 Outcome이 예측이 어려운 비선형 구조일 때 | 선형 모델 기반으로는 misspecification 위험 증가 |
| 🎲 Randomization 기반 분석이 더 타당한 경우 | 예: RCT 기반 데이터는 IPTW나 단순 비교가 더 직관적일 수 있음 |
✍ 구현 단계
🔹 Step 1: 데이터 정비
- 입력 데이터:
- A: 치료 변수 (1=처치, 0=비처치)
- Y: 결과 변수 (연속형 또는 이진)
- X: 공변량들 (confounder: 나이, 성별, 질병력 등)
- ⚠️ Confounder는 반드시 빠짐없이 포함해야 함
- 누락된 confounder가 있으면 결과는 편향됨.
🔹 Step 2: Outcome Model 학습
- 전체 데이터를 이용해 결과 Y를 A와 X로 예측하는 모델을 학습함.
- 선형 회귀, 로지스틱 회귀, 랜덤 포레스트, XGBoost 등 사용 가능
- 이 모델은 “이 환자가 처치를 받았을 때 결과가 어떻게 될까?”를 예측해주는 함수
- 예: Y = f(A, X)
model = LinearRegression().fit(X=[treatment, age, bmi, ..., other confounders], y=outcome)
🔹 Step 3: Counterfactual Dataset 생성
- 각 환자에 대해 A=1로 가정한 데이터셋, A=0으로 가정한 데이터셋을 각각 생성
df_cf1 = df.copy()
df_cf1['treatment'] = 1
df_cf0 = df.copy()
df_cf0['treatment'] = 0
🔹 Step 4: 예측값 계산
- 학습된 outcome model을 통해 각 환자에 대해
- Y^1 = f(1, X)
- Y^0 = f(0, X)
를 각각 예측
y_hat1 = model.predict(df_cf1)
y_hat0 = model.predict(df_cf0)
🔹 Step 5: ATE 계산
- 전체 집단에 대해 예측된 결과의 평균 차이를 계산
→ ATE (Average Treatment Effect) 추정
ATE = np.mean(y_hat1 - y_hat0)
🔹 Step 6 (Optional): Cross-Fitting (교차검증)
- 데이터 과적합 방지를 위해 K-fold cross-fitting을 수행
- 각각의 fold에서 모델을 학습하고, test fold에 counterfactual을 적용해 ATE를 반복 계산
- 평균 ATE를 최종 결과로 보고, 불확실성도 함께 평가 가능
🧠 예측 기반 인과추론의 핵심은?
- Outcome을 예측할 수 있는 충분히 정교한 모델
- 모델은 bias보다는 robustness를 추구해야
- confounder는 반드시 포함, mediator는 제외
- “예측 잘한다고 인과 잘 아는 건 아니다”라는 점을 늘 의식하기
🧠 추가 시각화 혹은 검정
- SHAP/Partial Dependence Plot으로 X변수가 Y에 미치는 영향 시각화
- Bootstrapping으로 신뢰구간 추정
- 다양한 ML 모델로 비교 (예: XGBoost, Random Forest, Lasso 등)

💬 요약
- 모델 학습: 결과 Y를 예측하는 함수 f(A, X) 학습
- Counterfactual 생성: 같은 환자에게 A=1, A=0을 각각 가정
- 평균 차이 계산: 전체 집단에 대해 두 예측값의 평균 차이 → ATE
📌 Outcome Model vs Treatment Model
- G-Computation은 Outcome 모델에 기반한다:
→ “결과가 어떻게 나올지를 예측” - 반면, Propensity Score 방법은 Treatment 모델:
→ “누가 처치를 받을 확률이 높은지를 예측”
| 비교 | G-Computation | Propensity Score |
| 모델 중심 | 결과 모델 | 처치 모델 |
| 접근 방식 | 결과를 시뮬레이션 | 처치 확률로 가중치 부여 |
| 민감성 | 결과 예측 정확도에 민감 | PS 추정 정확도에 민감 |
| 확장성 | 머신러닝, 앙상블 적용 쉬움 | 가중치 적용이 핵심 |
🔍 Outcome model 성능은 어떻게 평가할까?
🔍 예측 vs 인과 추론: 평가 기준이 다르다
G-Computation은 결과 예측 모델(outcome model)을 바탕으로 인과효과를 추정한다.
따라서 흔히 사용하는 AUC, RMSE 등의 예측 정확도 지표는 도움이 되지만, 그것만으로 충분하지 않다.
왜냐하면:
- 모델의 예측이 맞더라도 인과 구조를 잘못 추정하면 ATE는 틀릴 수 있고
- 반대로 예측 정확도는 낮더라도 인과 구조가 올바르면 ATE는 정확할 수 있다
📌 따라서 인과추론을 위한 모델 성능 평가는
bias + variance trade-off, robustness to misspecification, confounder 포함 여부에 기반해야 한다.
✅ 실무 팁:
- 예측 모델은 너무 복잡하지 않게 (과적합 피하기)
- 교차검증으로 평균 효과의 변동성 확인
- 가능한 여러 알고리즘을 사용해 결과 일관성 확인 (ensemble)
❗ 주의사항
- 모델 성능이 낮으면 추정치도 왜곡
- 모든 confounder가 포함되어야 한다
(confounding을 통제하지 않으면 인과효과 추정이 무의미) - Outcome 모델이 misspecified되면 큰 bias 발생
🧠 Outcome model이 불안정할 땐?
G-Computation은 outcome model에 전적으로 의존하므로, 다음과 같은 상황에서는 위험하다:
- confounder가 누락되어 있을 때
- 모델이 결과의 비선형 패턴을 포착하지 못할 때
- 특정 변수에 대한 처리효과가 비일관적일 때 (effect heterogeneity)
이런 상황에서는 다음 대안을 고려하자:
| 대안 | 요약 | 특이점 |
| DR Estimation | G-Computation + IPTW 결합 | 둘 중 하나만 맞아도 일관된 추정 가능 |
| Causal Forest | 효과가 집단마다 다를 때 추정 | 조건부 평균 인과효과(CATE) 추정 가능 |
| TMLE | targeting 단계로 bias 감소 | 통계학+머신러닝의 접점 |
🏥 임상 예시: 항고혈압제 효과
고혈압 환자에게 항고혈압제를 투여했을 때
→ 모든 환자에 대해 “약을 복용했을 때 vs 안 했을 때” 결과를 상상해보자.
- A: 약 복용 여부 (1: 복용, 0: 미복용)
- Y: 6개월 후 수축기 혈압
- X: 나이, 성별, 초기 혈압, 체중 등
📌 G-Computation은 다음을 수행한다:
- Y ~ f(A, X) 형태의 회귀모델 학습 (예: 선형회귀, 랜덤포레스트 등)
- 모든 환자에 대해
- A=1인 경우의 예측값 → Y^1
- A=0인 경우의 예측값 → Y^0
- 평균차이 계산 → ATE 추정
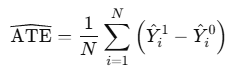
🧪 Python 실전 코드 예시 (Linear Regression 기반)
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
# 데이터 예시
df = pd.DataFrame({
'treatment': [1, 0, 1, 0, 1],
'age': [65, 70, 55, 60, 58],
'baseline_bp': [150, 160, 145, 155, 148],
'outcome': [130, 140, 125, 138, 128]
})
X = df[['treatment', 'age', 'baseline_bp']]
y = df['outcome']
# 모델 학습
model = LinearRegression().fit(X, y)
# Counterfactual 생성
X1 = df.copy()
X1['treatment'] = 1
X0 = df.copy()
X0['treatment'] = 0
# 예측
y1 = model.predict(X1)
y0 = model.predict(X0)
# ATE 계산
ate = np.mean(y1 - y0)
print("Estimated ATE:", ate)
🔁 Cross-Fitting으로 과적합 방지
from sklearn.model_selection import KFold
kf = KFold(n_splits=2, shuffle=True, random_state=42)
ates = []
for train_idx, test_idx in kf.split(df):
train = df.iloc[train_idx]
test = df.iloc[test_idx]
model = LogisticRegression()
model.fit(train[X_cols], train['event'])
test1 = test.copy(); test1['treatment'] = 1
test0 = test.copy(); test0['treatment'] = 0
y1 = model.predict_proba(test1[X_cols])[:, 1]
y0 = model.predict_proba(test0[X_cols])[:, 1]
ates.append(np.mean(y1 - y0))
print(f"Cross-Fitted ATE: {np.mean(ates):.3f}")
📦 확장: 머신러닝과 G-Computation의 결합
최근에는 G-Computation과 머신러닝 기법을 결합한 방법들이 주목받고 있다.
| 모델 | 특징 |
| Super Learner | 여러 ML 알고리즘을 앙상블 |
| BART (Bayesian Additive Regression Trees) | 비선형 인과 추정 |
| TMLE (Targeted Maximum Likelihood Estimation) | G-Computation + Propensity Score + targeting |
이러한 모델들은 G-Computation의 추론력은 유지하면서도
유연한 함수 형태와 높은 예측 정확도를 확보할 수 있게 해준다.
🔍 G-Computation vs IPTW vs TMLE 비교
| 접근법 | 특징 | 장점 | 단점 |
| G-Computation | 결과 예측 모델로 인과 추정 | 직관적, 머신러닝 활용 쉬움 | 모델 오차에 민감 |
| Propensity Score | 처치 확률 조정 | 해석 용이, RCT 유사 | 가중치 민감, 효율성↓ |
| TMLE | 통계학+ML 접점 | double robust, 정교함 | 구현 복잡 |
| 항목 | G-Computation | IPTW | TMLE |
| 사용 모델 | Outcome model | Treatment model | 둘 다 |
| Robustness | 낮음 | 낮음 | 높음 |
| 추정 대상 | ATE | ATE | ATE |
| 장점 | 구현 쉬움 | 전체 모집단 반영 | Doubly Robust |
| 단점 | 모델 오류 민감 | extreme weight | 복잡한 구현 |
✅ G-Computation이 잘 맞는 상황은?
- outcome이 연속형이고 예측이 잘 되는 경우 (e.g., 혈압, 체중)
- confounder가 대부분 관측된 경우
- 개별 환자 수준 counterfactual을 보고 싶은 경우
⚠️ 실무 체크리스트
| 항목 | 체크 내용 |
| 모델 선택 | 회귀 vs ML, 해석력 vs 성능 |
| 변수 선택 | Confounder만 포함, mediator 제외 |
| 검정 방법 | cross-validation, external validation |
| 효과 해석 | ATE = 전체 평균 효과 |
| 비교 방법 | PSM, IPTW 등과 병렬 분석 권장 |
📌 최종 정리
| 항목 | 설명 |
| G-Computation 정의 | 결과 예측 모델을 기반으로 counterfactual을 생성, 인과효과 추정 |
| 핵심 장점 | 전체 인과효과(ATE)를 직관적으로 추정 가능 |
| 필요한 조건 | 적절한 outcome model, 모든 confounder 포함, no unmeasured confounding |
| 확장성 | 머신러닝 기반 모델과 쉽게 결합 가능 |
| 실무 팁 | 교차검증 필수, mediator 제외, 변수 선택 신중 |
'실전 인과추론' 카테고리의 다른 글
| 《실전 인과추론 시리즈 ⑦ – TMLE 해부하기》 (2) | 2025.05.19 |
|---|---|
| 《실전 인과추론 시리즈 ⑥ - Marginal Structural Models(MSM) 해부하기》 (0) | 2025.05.14 |
| 《실전 인과추론 시리즈 ④ - RDD(단절설계) 해부하기》 (2) | 2025.05.12 |
| 《실전 인과추론 시리즈 ③ - Difference-in-Differences, DiD 해부하기》 (1) | 2025.05.11 |
| 《실전 인과추론 시리즈 ② - Instrumental Variable(도구변수) 해부하기》 (0) | 2025.05.08 |