

현실 데이터엔 결측값이 꼭 있다.
건강검진 데이터에서 혈압이나 공복혈당이 누락되었거나,
고객 이탈 예측에서 일부 고객의 사용 이력이 비어 있는 경우처럼.
많은 분석가는 이를 평균값이나 중앙값으로 간단히 채우고 넘어가지만,
이런 방식은 데이터의 불확실성을 완전히 무시하고 추정치를 과소평가하게 만든다.
특히 인과추론, 회귀모델, 정책 효과 평가처럼 추론 기반 분석에서는 치명적일 수 있다.
그렇다면 어떻게 해야 더 신뢰할 수 있을까?
그렇다면 변수 간의 관계를 고려하면서, 불확실성까지 반영하는 결측값 처리법은 없을까?
🔍 MICE란 무엇인가?
MICE (Multivariate Imputation by Chained Equations)는
결측값이 있는 각 변수에 대해, 나머지 변수들로 회귀모델을 학습하여 결측을 예측하고,
이 과정을 반복하여 점점 정교하게 채워가는 방식이다.
이러한 방식은 변수 간의 상호작용을 반영하며, 단순 대체보다 훨씬 정교한 대체가 가능하다.
scikit-learn의 IterativeImputer는 이 과정을 머신러닝 관점에서 구현한 대표적인 도구다.
✅ MICE 핵심 요약
- MICE는 다른 변수들을 이용해 결측값을 예측하는 방식이다.
- 기본적으로는 Bayesian Ridge Regression을 사용하며,
선형회귀/랜덤포레스트 등 다른 예측모델로도 대체할 수 있다. - 한 번이 아니라 여러 번 반복(iteration)하면서 결과를 점점 정교하게 만든다.
🔍 왜 MICE가 필요한가?
보통 우리는 이런 방식으로 결측값을 처리하곤 한다.
df.fillna(df.mean())
하지만 이건 전체 평균을 그냥 넣는 방식이라, 변수 간의 연관성을 무시한다.
예를 들어 혈압, 혈당, 중성지방 같이 서로 상관관계가 높은 변수들이 있다면?
👉🏻 서로를 이용해 결측값을 예측하는 게 더 합리적이다.
🧩 MICE 작동 원리
MICE는 기본적으로 다변량 회귀 방식을 사용한다.
🔧 작동 흐름은 이렇다:
- 초기값으로 임시 채우기 (예: 평균값)
- 각 변수에 대해, 해당 변수의 결측값을 타겟으로 하고
나머지 변수들을 설명 변수로 하여 예측모델을 학습 - 예측된 값으로 해당 변수의 결측값을 업데이트
- 모든 변수에 대해 반복 수행
- 이 과정을 여러 번 반복 (기본값: 10회)
📊 그래픽 예시:
- x축: 반복 회차(iteration)
- y축: 각 변수의 예측 정확도 또는 MSE

⚙️ Python 예시 : Iterative Imputer
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer
import pandas as pd
# 예시 데이터프레임
iterative_cols = ['bp', 'wc', 'fg', 'tg', 'hdl']
df_iter = df[iterative_cols].copy()
# Iterative Imputer 실행
imp_iter = IterativeImputer(max_iter=10, random_state=0)
df_iter_imputed = pd.DataFrame(imp_iter.fit_transform(df_iter), columns=iterative_cols)
# 결과 반영
df[iterative_cols] = df_iter_imputed
🔍 예측 모델 선택 가이드
기본적으로는 BayesianRidge 회귀를 사용하지만,
다음과 같이 다른 예측기를 쓸 수도 있다:
- DecisionTreeRegressor
- KNeighborsRegressor
- RandomForestRegressor
from sklearn.ensemble import RandomForestRegressor
imp_rf = IterativeImputer(estimator=RandomForestRegressor(), max_iter=10)
각 모델의 특징에 따라 예측 성능과 실행 시간이 달라진다.
🧠 실전 적용 팁
| 상황 | 추천 모델 | 이유 |
| 변수 간 선형 관계가 뚜렷 | BayesianRidge | 빠르고 안정적 |
| 비선형 관계가 있을 때 | RandomForestRegressor | 유연성 있음 |
| 소수의 결측치 | KNN | 빠르고 간단 |
| 수치형 변수 중심 | ✔️ 사용 권장 | 범주형은 라벨인코딩 필요 |
📌 주의:
- 범주형 변수에는 비적합하다. 수치로 변환한 뒤 사용해야 하며, 결과도 다시 변환해야 한다.
- 변수 간 강한 연관성이 있어야 효과적이다.
📈 다른 방식과 비교
| 방식 | 상호작용 고려 | 반복 학습 | 장점 | 단점 |
| 평균/중앙값 | ❌ | ❌ | 간단, 빠름 | 정보 손실 |
| KNN Imputer | ✅ (부분적) | ❌ | 이웃 기반 | 고차원에서 성능 저하 |
| Iterative Imputer | ✅ | ✅ | 관계 반영, 정교함 | 느릴 수 있음 |
💬 사고 확장 질문
Q1. 이 방식은 결측값이 많은 변수에는 여전히 한계가 있을까?
👉🏻 그렇다. 해당 변수의 관측치가 너무 적으면 모델 학습이 부정확해지고, 예측값의 신뢰도도 떨어진다.
Q2. 회귀 기반 예측보다 tree 기반 예측이 더 효과적일 상황은 언제일까?
👉🏻 변수 간 비선형 관계나 상호작용이 많을 때, 트리 기반 모델이 더 유연하게 패턴을 포착한다.
Q3. 다변량 결측 대체 후 변수 간 상관성이 인위적으로 강화되는 문제는 없을까?
👉🏻 있다. Imputer가 학습한 구조를 그대로 반영해 상관관계를 과도하게 강화시킬 수 있어, 주의가 필요하다.
🔍 Multiple MICE란 무엇인가?
Multiple MICE는 MICE(Multivariate Imputation by Chained Equations)를 여러 번 반복 수행하여
결측값을 서로 다르게 채운 복수의 데이터셋(imputed datasets)을 생성하는 방법이다.
단일 MICE는 하나의 대체값만 생성하지만,
Multiple MICE는 매번 약간씩 다른 예측값을 생성함으로써
결측값으로 인해 발생하는 추정의 불확실성까지 반영할 수 있도록 설계되었다.
이 방식은 특히 통계적 추론(inferential analysis)에서 매우 유용하다.
예를 들어, 회귀분석이나 평균 차이 검정처럼 표준오차(SE)와 신뢰구간(CI)이 중요한 분석에서는
단일 대체보다 Multiple Imputation이 더 신뢰할 수 있는 결과를 제공한다.
✅ Muptlie MICE 핵심 요약
- Multiple MICE는 MICE를 여러 번 반복해 결측값을 다르게 채운 여러 데이터셋(imputed datasets)을 만든다.
- 이를 통해 결측으로 인한 추정치의 불확실성까지 반영할 수 있다.
- miceforest는 이 과정을 Random Forest 기반으로 빠르고 강력하게 구현해주는 Python 패키지다.
- 마지막에 여러 분석 결과를 Rubin’s Rule로 통합하면, 결측값 처리 후에도 신뢰할 수 있는 추론이 가능하다.
🔍 왜 Multiple MICE가 필요한가?
단일 대체는 그럴듯한 하나의 값을 예측해서 넣어줄 뿐이다.
하지만 결측값은 본질적으로 '불확실성'을 가진 정보 손실이기 때문에,
이걸 감안하지 않으면 추정치의 표준오차(SE)가 과소평가될 수 있다.
Multiple MICE는 이를 막기 위해, 각 대체본마다 다른 예측값을 샘플링하여 여러 개의 데이터셋을 생성한다.
그리고 각각에 대해 분석을 수행한 뒤, 그 결과를 하나로 통합한다.
→ 이때 쓰이는 수학적 방법이 바로 Rubin's Rule이다.
🔄 단일 vs 다중 대체 비교
| 항목 | MICE (단일) | Multiple MICE |
| 결측 대체 횟수 | 1회 | 여러 번 (보통 5~20회) |
| 생성된 데이터셋 | 1개 | 여러 개 |
| 분석 결과 | 1개의 추정치 | 여러 추정치를 Rubin's Rule로 통합 |
| 불확실성 반영 | ❌ | ✅ (Standard Error, CI 반영 가능) |
⚙️ Python 예시 : Miceforest
import miceforest as mf
import pandas as pd
# 1. 데이터 준비
df = pd.read_csv('your_data.csv')
# 2. MICE 모델 생성 (Random Forest 기반)
kernel = mf.ImputationKernel(
df,
datasets=5, # 다중 대체본 개수
save_all_iterations=True,
random_state=42
)
# 3. Imputation 수행 (여러 번 반복)
kernel.mice(5) # 5번 반복
# 4. 대체된 데이터셋 가져오기
completed_df1 = kernel.complete_data(dataset=0)
completed_df2 = kernel.complete_data(dataset=1)
# ...
📐 Rubin’s Rule – 분석 결과 통합
대체된 각 데이터셋에서 동일한 모델 (ex: 회귀분석)을 수행한 후,
각 모델의 추정치(β̂)와 표준오차(SE)를 통합:
1. 평균 추정치
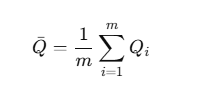
2. 평균 내적 분산 (within-imputation variance)

3. 대체 간 분산 (between-imputation variance)
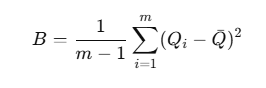
4. 총 분산

→ 최종 표준오차(SE)는 sqrt{T},
→ 신뢰구간 계산 및 p-value 추정 가능
🧠 실전 적용 팁
- 결측률이 높을수록 Multiple MICE가 더 유리하다.
- 데이터가 복잡하거나 변수 간 관계가 비선형이라면 → miceforest 추천
- 분석 결과를 리포트/논문에 넣을 때, Rubin’s Rule을 적용한 CI와 SE를 명시해야 통계적으로 타당하다.
⚠️ 주의할 점
| 항목 | 설명 |
| 데이터 구조 | 범주형 변수는 encoding 필수 |
| 모델 적합 시간 | Random Forest 기반이라도 다중 대체는 시간 소요 |
| 샘플 수 | 데이터셋 수가 너무 작으면 between variance가 불안정함 |
💬 사고 확장 질문
Q1. 결측률이 매우 낮은 경우에도 Multiple MICE를 적용하는 게 좋을까?
👉🏻 필요 없다. 결측이 적으면 단일 MICE로도 충분하며, Multiple MICE는 계산 부담만 늘고 과적합 위험도 있을 수 있다.
Q2. Rubin’s Rule 없이 평균만 내면 어떤 문제가 생길까?
👉🏻 불확실성이 과소평가되어 표준오차(SE)가 낮아지고, 신뢰구간이나 p-value 해석이 왜곡될 수 있다.
Q3. 머신러닝 모델 예측 성능 중심이라면, 단일 MICE로도 충분한가?
이제 결측값은 '채우는 것'이 아니라, '예측하고 해석하는 것'이다.
단순 대체에서 벗어나, 이제는 MICE와 Multiple MICE를 통해 데이터의 불확실성까지 이해하자.
'데이터분석' 카테고리의 다른 글
| 📊 의료 논문에서 꼭 나오는 통계 지표 9가지 완전 정복 (0) | 2025.05.20 |
|---|---|
| [생존분석] RMST vs. AFT 모델 완전 정리 (2) | 2025.05.16 |
| [데이터분석] 📚 결측치 처리와 인과추론, 함께 이해하기 (0) | 2025.04.26 |
| [데이터분석] 📊 이상치(Outlier) 처리, 완전 실무형 정리 (2) | 2025.04.26 |
| [데이터분석]🧹 결측, 그 빈칸을 채우는 법 (3) | 2025.04.25 |